Data Mining Algorithms In R/Packages/FactoMineR
FactoMineR is an R package dedicated to multivariate data analysis. The main features of this package is the possibility to take into account different types of variables (quantitative or categorical), different types of structure on the data (a partition on the variables, a hierarchy on the variables, a partition on the individuals) and finally supplementary information (supplementary individuals and variables). Moreover, the dimensions issued from the different exploratory data analyses can be automatically described by quantitative and/or categorical variables. Numerous graphics are also available with various options. Finally, a graphical user interface is implemented within the Rcmdr environment in order to propose a user friendly package.
Methods
[edit | edit source]The methods implemented in this package are conceptually similar with respect to its main goal, for example, merge and simplify the data by reducing the dimensionality of the data set. These methods are used depending on what data are available and if the variables are quantitative (Numerous) or qualitative (categorical or nominal).
Several methods are implemented, the most classical (PCA, Correspondence Analysis, Multiple Correspondence Analysis, Multiple Factor Analysis) as well as some advanced methods (Hierarchical Multiple Factor Analysis, Mixed Data Analysis, Dual Multiple Factor Analysis).
For the classical ones we have the following situation-use solutions:
- Principal component analysis (PCA) when individuals are described by quantitative variables;
- Correspondence analysis (CA) when individuals are described by two categorical variables that leads to a contingency table;
- Multiple correspondence analysis (MCA) when individuals are described by categorical variables.
And for the advanced methods:
- MFA (Multiple Factorial Analysis), for which the variables of a same group may be numerical or categorical.
- HMFA (Hierarchical Multiple Factorial Analysis), an extension of MFA for which variables are structured according to a hierarchy.
- GPA (Generalized Procustean Analysis), for which variables must be continuous.
Let X be the data table of interest. In order to reduce the dimensionality, X is transformed to a new coordinate system by an orthogonal linear transformation. Let Fs (resp. Gs ) denotes the vector of the coordinates of the rows (resp. columns) on the axis of rank s. Those two vectors are related by the so called “transition formulae”. In the case of PCA, they can be written:


where Fs (i) denotes the coordinate of the individual i on the axis s, Gs (k) the coordinate of the variable k on the axis s, λs the eigenvalue associated with the axis s, mk the weight associated to the variable k, pi the weight associated to the individual i, xik the general term of the data table (row i, column k).
The transition formulae lay the foundation of our point of view and consequently set the graphical outputs at the roots of our practice. From these formulae it is crucial to analyze the scatter plots of the individuals and of the variables conjointly: an individual is at the same side as the variables for which it takes high values, and at the opposite side of the variables for which it takes low values.
Supplementary elements
[edit | edit source]Another important feature of the transition formulae is that they can be applied to supplementary individuals and/or variables in order to add supplementary information on the scatter plots for a better understanding of the data. In the PCA framework, let i' be a new individual, its coordinate on the axis of rank s can be easily obtained as followed:

In the same manner, it is also easy to calculate the coordinate of a supplementary variable when the former is quantitative; in this case the supplementary variable lies in the scatter plot of the variables. When the variable is categorical, its modalities are represented by the way of a “mean individual” per modality. For each modality, the values associated with each “mean individual” are the means of each variable over the individuals endowed with this modality; in this case the supplementary variable lies in the scatter plot of the individuals.
Implementation
[edit | edit source]Installation
[edit | edit source]Load FactoMineR in your R session by writing the following line code:
library(FactoMineR)
to Download the graphical interface of FactoMineR in your R session write the following line code (you have to be connected to internet):
source("http://factominer.free.fr/install-facto.r")
Loading and using
[edit | edit source]Load FactoMineR for each new R session by typing the following line code:
library(FactoMineR)
Or load FactoMineR and its GUI for each new R session by typing the following line code:
library(Rcmdr)
Functions Reference
[edit | edit source]A complete implementation reference of all fifty FactoMineR functions, with description, usage, arguments and values, can be foud here
Visualization
[edit | edit source]With the function plot, you can draw graphs and results. Usage:
R> plot(<method>,<what variable to color individuals from>)
-
 Decathlon data - available with the package documentation) : supplementary variables are in blue
Decathlon data - available with the package documentation) : supplementary variables are in blue -
 Individuals graph (Decathlon data - - available with the package documentation): individuals are colored from the athletics meeting
Individuals graph (Decathlon data - - available with the package documentation): individuals are colored from the athletics meeting


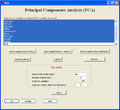
With the graphical interface of FactoMineR, you can perform easily and intuitive tasks. As an example, we have the interface for the PCA function: The main window allows to choose the active variables (by default all the variables are active and the PCA can be performed). Several buttons allow to choose the supplementary quantitative or categorical variables, the supplementary individuals, the outputs to be displayed or the graphs to be plotted.
-
 Individuals graph (Decathlon data - - available with the package documentation): individuals are colored from the athletics meeting
Individuals graph (Decathlon data - - available with the package documentation): individuals are colored from the athletics meeting

Example
[edit | edit source]As an example, we use here a data set issued from a questionnaire about French women's work in 1974. You can load the data set here.
Presentation of the data
[edit | edit source]1724 women have answered several questions about women's work among which:
* What do you think the perfect family is ?
o Both husband and wife work
o Husband works more than wife
o Only husband works
* Which activity is the best for a mother when children go to school?
o Stay at home
o Part-time work
o Full-time work
* What do you think of the following sentence: women who do not work feel cut off from the world?
o Totally agree
o Quite agree
o Quite disagree
o Totally disagree
The data set is two contingency tables which cross the answers of the first question with the two others. To each crossing, the value given is the number of women who gave both answers.

To load the package and the data set, write the following line code:
library(FactoMineR)
women_work=read.table("http://factominer.free.fr/classical-methods/datasets/women_work.txt", header=TRUE, row.names=1, sep="\t")
Objectives
[edit | edit source]The objectives of CA are quite the same as PCA's: to get a typology of rows and columns and to study the link between these two typologies. However, the concept of similarity between rows or columns is different. Here, similarity between two rows or two columns is completely symmetric. Two rows (resp. columns) will be close to each other if they associate with the columns (resp. rows) in the same way.
We are looking for the rows (resp. columns) whose distribution is the most different from the population's. The ones which look the most or the less alike. Each group of rows (resp. columns) is characterized by the columns (resp. rows) to which it is too much or to little associated.
CA
[edit | edit source]We are going to use the first three columns (corresponding to the answers to the second question) as active variables and the four last ones (corresponding to the third question) as supplementary variables.
- Active rows and columns only
To see the scatterplots of rows and columns separately, type:
res.ca.rows = CA(women_work[,1:3], invisible="col")
res.ca.col = CA(women_work[,1:3], invisible="row")
#women_work: the data set used
#invisible: elements we do not want to be plotted


On the scatterplot of the columns, we can see that the first axis opposes "Stay at home" and "Full-time work", which means it opposes two women's profiles. Women who answered "Stay at home" answered "Only husband works" more often than the population and "Both husband and wife work" less often than the population. In the same way, women who answered "Full-time work" answered "Only husband works" less often than the population and "Both husband and wife work" more often than the population. The first axis orders the categories of the second question from the less to the most in favour of women's work.
We can make the same interpretation for the first axis of the row's scatterplot. The categories are sorted from the less ("Only husband works") to the most ("Both husband and wife work") in favour of women's work.
To have the representation of both rows and columns, type:
res.ca = CA(women_work[,1:3])
#women_work: the data set used
"Stay at home" is much associated with "Only husband works" and little associated to the two other categories.
"Both husband and wife work" is associated with "Full-time work" and opposed to "Stay at home".
- Addition of supplementary columns
We now add the columns corresponding to the third question as supplementary variables. Type:
res.ca = CA(women_work, col.sup=4:ncol(women_work))
#women_work: the data set used
#col.sup: vector of the indexes of the supplementary columns
"Totally agree" and "Quite agree" for "Women who do not work feel cut off from the world" are close to categories in favour of women's work. "Quite disagree" and "Totally "disagree" are close to categories opposed to women's work.