Financial Modelling in Microsoft Excel/Analysis
Making sense of the results is crucial. The first test is that your results give you the information you need to analyse the client problem.
Then you need to play with the model to test the effect of different inputs, to get a feel for the sensitivity to change. Ideally, you want results which are robust (i.e. they are not too sensitive to your inputs).
Testing the effect of uncertainty[edit | edit source]
All financial modelling is uncertain, because we can’t predict the future, and things may not go according to our assumptions.
The power of models is that they are dynamic (this was seen as a key advantage of the first spreadsheet, Visicalc). You can change an assumption and see the effect immediately.
Read this paper [1] on project financing, especially section 3.2, for more on sensitivity testing.
Base case[edit | edit source]
You will usually start with a “base case” set of assumptions and inputs. These are your best estimates, and you would use these to produce a set of expected results.
Scenario testing[edit | edit source]
It is common to set up alternative scenarios, e.g. pessimistic, expected and optimistic, and run them through a model. Each scenario will consist of a set of assumptions and inputs chosen by the user. Importantly, the assumptions need to be consistent, so for example, if you assume inflation is only 2%, salary growth is likely to be low as well.

This approach is very useful for business planning and risk management, because it shows the impact of different conditions.
Scenario testing is quick and it is easy to present the results to management, to show them best & worst case extremes. On the other hand, it can’t tell you how likely it is that each scenario will occur, or whether there are other important scenarios that need to be tested. You are relying entirely on the skill and experience of whoever sets up the scenarios, and hoping they thought of everything.
To summarise, this approach
- lets us see the effect of a worst case and best case alternative to our expected result,
- is simple to set up in a spreadsheet, &
- makes it simple to present alternatives to clients.
The weakness is that
- you don’t know how likely each scenario is,
- you can’t give an estimate of the average result, taking into account the full range of alternatives, and
- you can’t estimate the range of likely results or produce percentiles.
Note: Excel has a “scenarios” feature which lets you store values for a number of inputs under a scenario name. The problem is that the scenario details are hidden. It is better to set up all the scenarios in a table (like the example above) so they can be compared easily.'
Stress testing[edit | edit source]
Stress testing is linked to scenario testing. Suppose you have built a model of an insurer’s financial position into the future. You would “stress test” the insurer by setting up various catastrophe scenarios and then modelling the financial position in each case. Ideally, the insurer will survive each one.
Stress tests can be based on actual past events, or on imagined events.
Like stochastic testing (below), it can be difficult to set the assumptions, as this extract of a US report on one of their housing agencies shows: With basic model development complete, we are now well into sensitivity testing; that is, running complete sets of actual Enterprise data through the model to evaluate the appropriateness of various "settings" of its components for the stress test. For example, we must determine the appropriate specification governing the shape of the Treasury yield curve, the relationship between Treasury rates and Enterprise borrowing rates, and the relationship between house prices and interest rates. These full-fledged simulation runs help us evaluate stress test options, and also provide the additional benefit of helping to identify possible model anomalies or program bugs that we need to address.
This is standard in a model development project of this type.
Sensitivity testing[edit | edit source]
A model can also be used to show the impact of changing one assumption, or perhaps a few linked assumptions. This sensitivity testing can show which inputs have the greatest effect on results.

Sensitivity testing can also test if the model is realistic, because users will generally have some idea of what to expect when they make a change.
Sensitivity testing can also help show whether a model is accurate enough. Suppose, for example, a company has a budget model, and it needs a model to be accurate to within $2 million. Sensitivity testing might show that the assumption with most impact is the investment rate, and that a change of just 0.5% in that rate has an impact of $2 million. This means that the user has to choose an investment assumption that is no more than 0.5% different from the actual rate (which we don’t know yet, because it is in the future). If the user can’t be sure of being this accurate, then the model can’t deliver the accuracy that the company wants.
Sensitivity testing is a powerful way of spotlighting parts of the model. It deepens your understanding of how the model reacts to change, and you should use it to gain familiarity with new models that you have not worked with before.
Sensitivity testing has its limitations. You have to be careful how much you change each assumption, and how you compare the sensitivity of one assumption against that of another.
Because it focuses on changing one (or maybe a few) elements at once, to see the effect, you can’t get a feeling for worst or best cases, nor for the probability of good or bad results. So it should be used together with other tests, and not on its own.
Probabilistic stochastic testing[edit | edit source]
Stochastic testing uses random numbers to simulate a large number of alternative scenarios that might happen in real life. We can then calculate percentiles to get some idea of the probability of different financial outcomes.
Example: an actuary wants to assess the likelihood that a fund will be insolvent in the future because of poor investment returns. She uses an investment model to produce (say) 1,000 separate sets of simulated investment returns, which might look something like this….
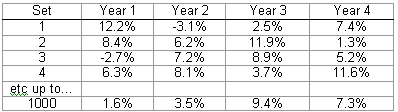

Each set of rates is put into the model, so there will be 1,000 sets of results. These can be sorted to find (say) the 10% and 90% percentiles, which gives the actuary a feel for how well – or badly – things could go in future.
Stochastic testing has the great benefit that it gives you a much better feel for the possible range of experience, either high or low.
Unfortunately, it is also the most complex to build, and it requires more complex assumptions, e.g. a statistical distribution for interest rates, and another for salary growth – and you have to consider whether there is a correlation between them that needs to be accounted for, so perhaps the distributions are connected.
It is very difficult to build a stochastic model of investment markets because of all these issues. It is much easier to model mortality stochastically.
Stochastic testing as a search tool[edit | edit source]
There is another way to use stochastic testing in your analysis. If you have a number of inputs, and each of them can vary in a range, then that is a very large number of combinations of inputs that may need to be tested in case they are important.
A simple way of approximating this is to create a large number of sets of inputs stochastically, i.e. choose each input randomly within the range you have set for it.
Below is an example….

etc.
Each of these sets can be run through the model, and the results sorted to see if there is any pattern, e.g. what inputs always give a high result, for example?
This is a quick and dirty way of trying most combinations of inputs.
Dynamic analysis[edit | edit source]
Some models need to include a feedback loop because the assumptions and inputs would not stay fixed over time, in the real world.
For example, if you are modelling a pension fund, and the assets fall below liabilities, the employer would most probably make extra payments to remove the shortfall. Your model may need to allow for this by including an algorithm that models the employer response to the financial position.
If you are modelling a banking nor financing institution and , somehow debit transactions sums up to be more than credit transactions , than we do need have to loop around to read the transactions again.